Run a microVM with a GPU mounted for Ollama¶
Ollama can run in any microVM using its CPU, however a GPU is the best option for a high token throughput and faster response times.
You'll need a PC with VFIO support, this allows a PCI device such as a GPU to be passed through to the microVM for exclusive access.
What if you have multiple GPUs? Let's imagine you have a ATX tower PC with 2x Nvidia RTX 3090 or 3060 GPUs.
- Allocate both GPUs to one machine
- Allocate each GPU to its own microVM
- Start up with zero microVMs and launch up to two short-lived tasks at once
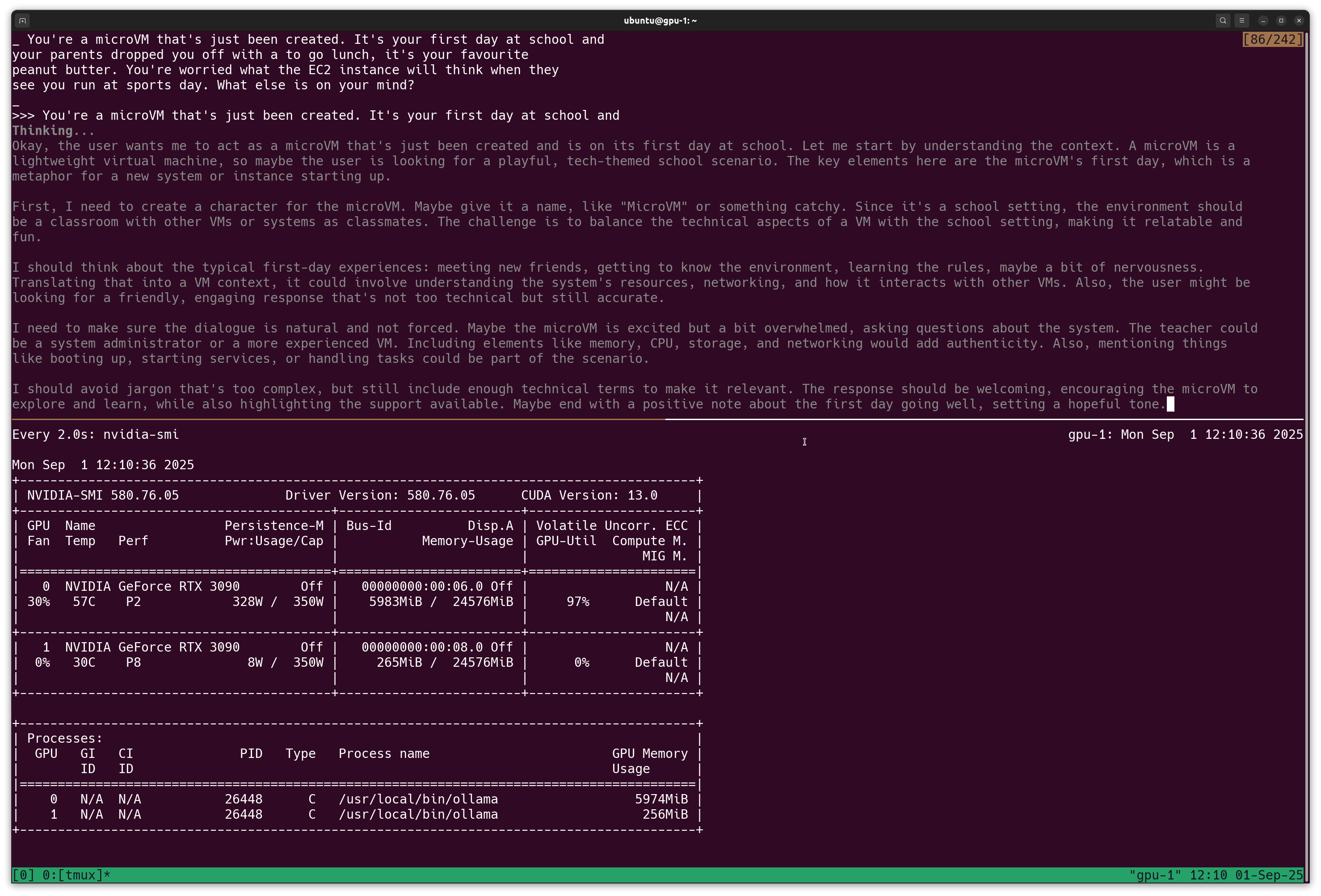
Ollama running the qwen3 model to generate a story about a microVM's first day at school.
GPU / VFIO mounting only works with Slicer running on x86_64 at present.
Set up your VM configuration¶
There a three differences to the other examples we've seen so far:
gpu_count: Nis added to the hostgroup, N is a the number of GPUs to allocate to each VMhypervisor: qemu- QEMU is used instead of Firecracker, to enable VFIO passthrough of a PCI deviceimage- a separate Kernel and root filesystem is required for QEMU
The following to gpu.yaml, make sure you update vcpu and ram_gb
config:
host_groups:
- name: gpu
storage: image
storage_size: 80G
count: 1
vcpu: 16
ram_gb: 64
gpu_count: 1
network:
bridge: brgpu0
tap_prefix: gputap
gateway: 192.168.137.1/24
github_user: alexellis
image: "ghcr.io/openfaasltd/slicer-systemd-ch:6.1.90-x86_64-latest"
hypervisor: qemu
Boot the VM(s) with:
sudo slicer up ./ollama-gpu.yaml
Note: adding PCI devices will add a boot delay of a few seconds vs. microVMs without any PCI devices. To monitor this, run ping in the background or sudo fstail /var/log/slicer/ to see when the dmesg messages start appearing.
Then, as usual, add the route on your workstation so you can connect via SSH.
ssh ubuntu@192.168.137.2
View the PCI devices:
$ lspci
00:00.0 Host bridge: Intel Corporation Device 0d57
00:01.0 Unassigned class [ffff]: Red Hat, Inc. Virtio console (rev 01)
00:02.0 Mass storage controller: Red Hat, Inc. Virtio block device (rev 01)
00:03.0 Mass storage controller: Red Hat, Inc. Virtio block device (rev 01)
00:04.0 Ethernet controller: Red Hat, Inc. Virtio network device (rev 01)
00:05.0 Unassigned class [ffff]: Red Hat, Inc. Virtio RNG (rev 01)
00:06.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
00:07.0 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
00:08.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
00:09.0 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)
You can see that I mounted 2x Nvidia RTX 3090 GPUs into this microVM.
You can install the Nvidia drivers using our utility script:
curl -SLsO https://raw.githubusercontent.com/self-actuated/nvidia-run/refs/heads/master/setup-nvidia-run.sh
chmod +x ./setup-nvidia-run.sh
echo "Downloading and installing Nvidia drivers... via nvidia.run"
sudo bash ./setup-nvidia-run.sh
Compilation can take a minute or two, but can be sped up by caching all changed files and untaring them over the top of the root filesystem in userdata, or by building a custom VM image with the generated tar expanded.
If you run into an error, you can edit the script and uncomment the line --no-unified-memory.
Other commands to start a custom agent, or to install frameworks/tools can be added easily via userdata directly within the YAML.
Check the status of the driver with nvidia-smi:
ubuntu@gpu-1:~$ nvidia-smi
Mon Sep 1 11:28:45 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.76.05 Driver Version: 580.76.05 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:00:06.0 Off | N/A |
| 30% 40C P0 108W / 350W | 0MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:00:08.0 Off | N/A |
| 30% 32C P0 99W / 350W | 0MiB / 24576MiB | 2% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Then install Ollama:
sudo apt update -qy && \
sudo apt install -qy zstd
curl -fsSL https://ollama.com/install.sh | sh
If you want to access the API from another machine, you can edit the service definition.
Edit /etc/systemd/system/ollama.service and add the following line under the [Service] section:
Environment="OLLAMA_HOST=0.0.0.0:11434"
Then restart the service:
sudo systemctl daemon-reload && \
sudo systemctl restart ollama
Next, pull a model and try out a prompt:
ollama run qwen3:latest
You can also connect to the Ollama API from your host machine by using the VM's IP directly:
curl -SLs http://192.168.137.2:11434/api/generate -d '{
"model": "qwen3:latest",
"prompt":"Why is the sky blue?"
}'
Since we're using a persistent disk image, any models you download will be available if you restart or shutdown Slicer.